IA : Anthropic revela Opus 4.8, apenas seis semanas após Opus 4.7
O mercado de modelos avançados evolui a um ritmo acelerado, impulsionado por atualizações frequentes e testes cada vez mais precisos. A Anthropic retorna com o Opus 4.8, uma versão que visa melhores desempenhos sem aumento do preço padrão. No setor de IA, este anúncio se destaca por seus resultados em programação, seus novos ajustes de esforço e seus progressos anunciados em termos de segurança.

Em resumo
- A Anthropic lança o Opus 4.8 apenas seis semanas após o Opus 4.7, com melhor desempenho e preço padrão inalterado.
- O modelo avança em vários benchmarks, especialmente no SWE-bench Pro, onde alcança 69,2% contra 64,3% do Opus 4.7.
- Opus 4.8 oferece um modo rápido, mais caro, mas anunciado como mais barato que os modos rápidos das versões anteriores.
- Os novos ajustes de esforço permitem adaptar o modelo conforme a velocidade, precisão e complexidade das tarefas.
- A Anthropic destaca também progressos em segurança, com menos enganos e menos bugs deixados sem reporte.
Anthropic lança Opus 4.8 pouco depois do Opus 4.7
Apenas seis semanas após o lançamento do Opus 4.7, a Anthropic apresenta o Opus 4.8 com uma promessa brilhante: melhorar o desempenho mantendo o mesmo preço. O modelo continua disponível por 5 dólares por milhão de tokens de entrada e 25 por milhão de saída. Essa estabilidade oferece uma referência útil para os usuários que comparam os custos entre as versões do Claude.
No entanto, o custo real pode variar conforme as tarefas. O novo tokenizer usa mais tokens para executar certas demandas. Assim, um trabalho feito com Opus pode custar mais do que com o Claude Sonnet. Este último é menos potente, mas pode ser suficiente para usos cotidianos ou problemas complexos que não envolvam pesquisa avançada.
Em paralelo, a Anthropic oferece um modo ágil para o Opus 4.8. Este modo executa o mesmo modelo a uma velocidade 2,5 vezes maior. O preço passa a ser 10 dólares por milhão de tokens de entrada e 50 por milhão de saída. Segundo a empresa, esse modo agora custa três vezes menos que os modos velozes dos modelos anteriores.
IA: desempenhos crescentes nos benchmarks
O resultado mais observado refere-se ao SWE-bench Pro. Este teste mede a capacidade de uma IA de resolver problemas complexos de engenharia de software em bases reais de código. O Opus 4.8 alcança 69,2%, contra 64,3% do Opus 4.7. Ele também supera o GPT-5.5, avaliado em 58,6%, e o Gemini 3.1 Pro, avaliado em 54,2%.
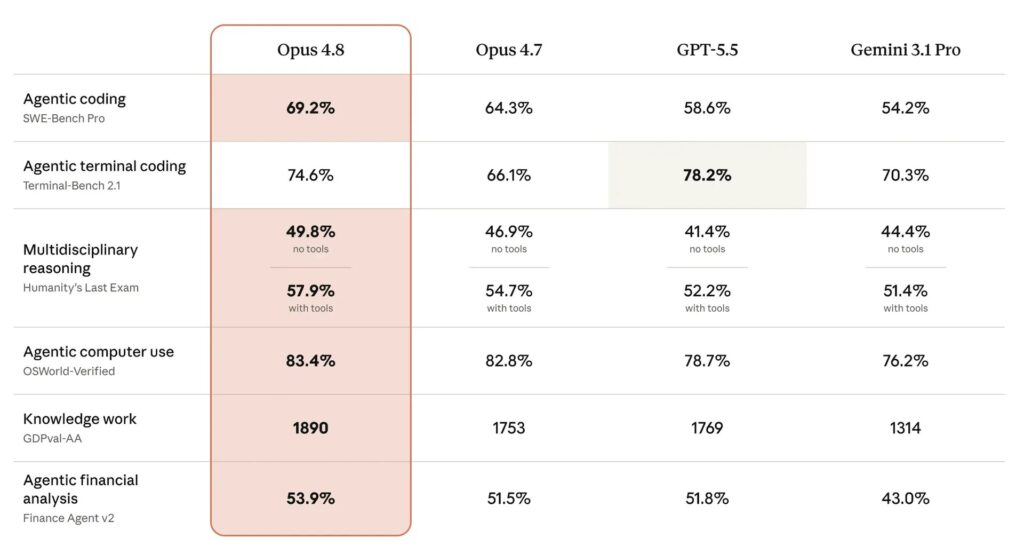
No Humanity’s Last Exam, o modelo também demonstra pontuações elevadas. Este questionário abrange várias disciplinas universitárias com perguntas em nível expert.
- Opus 4.8 obtém 49,8% sem ferramentas.
- Opus 4.8 atinge 57,9% com ferramentas.
- GPT-5.5 chega a 78,2% no Terminal-Bench 2.1.
- Opus 4.8 obtém 74,6% no Terminal-Bench 2.1.
- Opus 4.7 mostrava 66,1% neste mesmo teste.
- Opus 4.8 alcança 83,4% no OSWorld-Verified, contra 82,8% do Opus 4.7.
Esses resultados colocam o modelo à frente dos concorrentes citados nos dados fornecidos sobre o Humanity’s Last Exam. Os resultados são mais equilibrados no Terminal-Bench 2.1, que avalia tarefas de linha de comando feitas por uma IA. Apesar do segundo lugar, a Anthropic melhora significativamente a pontuação do Opus 4.7. No OSWorld-Verified, o modelo apresenta avanço mais sutil em relação à versão anterior.
Ajustes de esforço para melhor controlar o Claude
Opus 4.8 oferece mais controle aos usuários. Eles podem ajustar o nível de esforço do modelo conforme a dificuldade da tarefa. O nível alto permanece ativado por padrão e é adequado para a maioria das demandas. O nível Extra concede mais recursos para problemas complexos, enquanto o Max vai ainda mais longe.
Por outro lado, os níveis baixo e médio reduzem os recursos usados. Podem economizar tempo, mas também diminuem a precisão esperada. Essa escolha permite adaptar a IA de acordo com o orçamento, a velocidade desejada e a complexidade do trabalho.
Esse controle aparece próximo ao seletor de modelo em claude.ai e Cowork. Permanece disponível para todas as assinaturas. A Anthropic indica que o nível Alto consome quase tantos tokens quanto a configuração padrão do Opus 4.7, ao mesmo tempo em que oferece melhores resultados. Os limites de taxa no Claude Code também foram aumentados para absorver os usos dos níveis Extra e Max.
Segurança e comparação com Claude Mythos Preview
A equipe de alinhamento da Anthropic também destaca progressos no comportamento do modelo. Os dados indicam menos engano e menos cooperação em caso de uso abusivo. O Opus 4.8 também deixaria passar quatro vezes menos bugs em seu próprio código sem reportá-los.
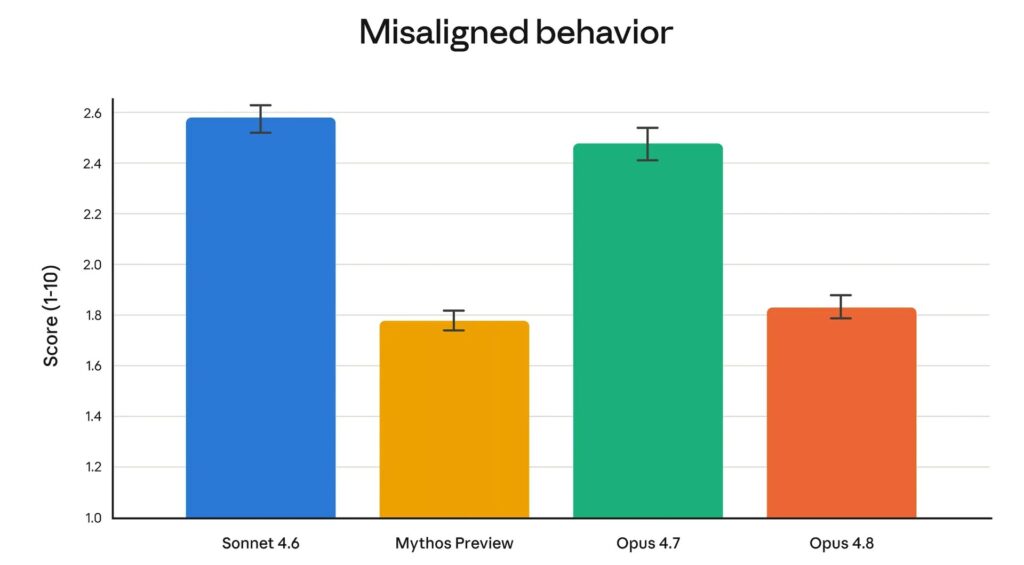
Esses resultados aproximam o Opus 4.8 do Claude Mythos Preview em certos critérios de segurança. No entanto, este último continua sendo apresentado como um modelo maior e mais inteligente que o Opus. Está disponível apenas em versão preliminar para algumas organizações selecionadas na área de cibersegurança, especialmente via o projeto Glasswing.
Esse âmbito limitado se explica por suas capacidades avançadas. O Instituto Britânico de Segurança em IA constatou que o Mythos poderia realizar sozinho uma simulação de ataque de rede em 32 etapas. Essa tarefa normalmente leva 20 horas para equipes especializadas em segurança. Por essa razão, o modelo ainda não é comercializado em larga escala.
A curto prazo, o Opus 4.8 deve sobretudo reforçar a concorrência entre Claude, GPT e Gemini. O desafio estará no equilíbrio entre custo, velocidade, precisão e segurança. Nesse contexto, a inteligência artificial não depende mais apenas das pontuações nos testes, mas também do controle oferecido aos usuários e dos limites estabelecidos para o seu uso.
Maximize sua experiência na Cointribune com nosso programa "Read to Earn"! Para cada artigo que você lê, ganhe pontos e acesse recompensas exclusivas. Inscreva-se agora e comece a acumular vantagens.

Journaliste et rédacteur web passionné par l’univers des cryptomonnaies et des technologies Web3. J’y traite les dernières tendances et actualités afin de proposer un contenu de haute qualité à un large public du secteur.
As opiniões e declarações expressas neste artigo são de responsabilidade exclusiva do autor e não devem ser consideradas como recomendações de investimento. Faça sua própria pesquisa antes de tomar qualquer decisão de investimento.