IA : Anthropic revela Opus 4.8, solo seis semanas después de Opus 4.7
El mercado de modelos avanzados evoluciona a un ritmo sostenido, impulsado por actualizaciones frecuentes y pruebas cada vez más precisas. Anthropic regresa con Opus 4.8, una versión que apunta a un mejor desempeño sin aumento en la tarifa estándar. En el sector de la IA, este anuncio se distingue por sus resultados en programación, sus nuevos ajustes de esfuerzo y sus progresos anunciados en materia de seguridad.

En resumen
- Anthropic lanza Opus 4.8 solo seis semanas después de Opus 4.7, con mejor desempeño y tarifa estándar sin cambios.
- El modelo avanza en varios benchmarks, especialmente SWE-bench Pro, donde alcanza 69,2 % frente a 64,3 % de Opus 4.7.
- Opus 4.8 ofrece un modo rápido, más costoso, pero anunciado como más barato que los modos rápidos de versiones previas.
- Los nuevos ajustes de esfuerzo permiten adaptar el modelo según la velocidad, precisión y complejidad de las tareas.
- Anthropic destaca también avances en seguridad, con menos engaños y menos bugs sin reportar.
Anthropic lanza Opus 4.8 poco después de Opus 4.7
Solo seis semanas después del lanzamiento de Opus 4.7, Anthropic presenta Opus 4.8 con una promesa brillante: mejorar el desempeño manteniendo el mismo precio. El modelo sigue ofrecido a 5 dólares por millón de tokens de entrada y 25 dólares por millón de tokens de salida. Esta estabilidad proporciona un referente útil para los usuarios que comparan costos entre las versiones de Claude.
Sin embargo, el costo real puede variar según las tareas. El nuevo tokenizador usa más tokens para ejecutar ciertas solicitudes. Así, un trabajo realizado con Opus puede costar más que con Claude Sonnet. Este último sigue siendo menos potente, pero puede ser suficiente para usos cotidianos o problemas complejos que no requieran investigación avanzada.
Paralelamente, Anthropic propone un modo rápido para Opus 4.8. Este modo ejecuta el mismo modelo a una velocidad 2,5 veces mayor. La tarifa pasa a 10 dólares por millón de tokens de entrada y 50 por el de salida. Según la empresa, este modo ahora cuesta tres veces menos que en modelos anteriores.
IA: desempeño en aumento en los benchmarks
El resultado más observado corresponde a SWE-bench Pro. Esta prueba mide la capacidad de una IA para resolver problemas complejos de ingeniería de software en bases reales de código. Opus 4.8 alcanza 69,2 %, frente a 64,3 % de Opus 4.7. También supera a GPT-5.5, calificado en 58,6 %, y a Gemini 3.1 Pro, calificado en 54,2 %.
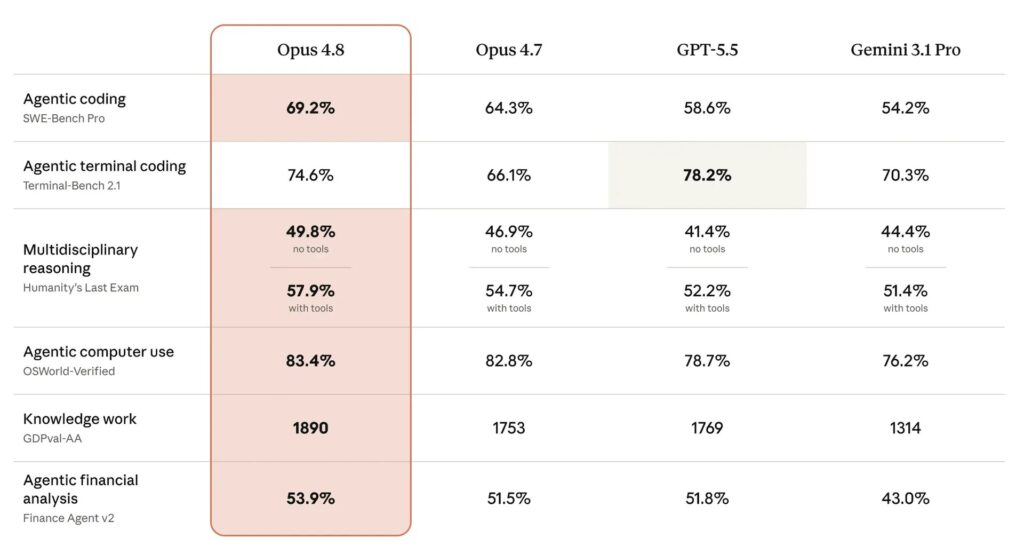
En Humanity’s Last Exam, el modelo también muestra puntuaciones altas. Este cuestionario cubre diversas disciplinas universitarias con preguntas de nivel experto.
- Opus 4.8 obtiene 49,8 % sin herramientas.
- Opus 4.8 alcanza 57,9 % con herramientas.
- GPT-5.5 alcanza 78,2 % en Terminal-Bench 2.1.
- Opus 4.8 obtiene 74,6 % en Terminal-Bench 2.1.
- Opus 4.7 mostraba 66,1 % en esta misma prueba.
- Opus 4.8 alcanza 83,4 % en OSWorld-Verified, frente a 82,8 % de Opus 4.7.
Estos resultados sitúan al modelo por delante de los competidores citados en los datos proporcionados sobre Humanity’s Last Exam. Los resultados son más matizados en Terminal-Bench 2.1, que evalúa tareas de línea de comandos realizadas por una IA. A pesar de su segundo lugar, Anthropic mejora notablemente la puntuación de Opus 4.7. En OSWorld-Verified, el modelo progresa más ligeramente respecto a la versión anterior.
Ajustes de esfuerzo para mejor controlar a Claude
Opus 4.8 da más control a los usuarios. Pueden ajustar el nivel de esfuerzo del modelo según la dificultad de la tarea. El nivel alto permanece activado por defecto y se adecua para la mayoría de las solicitudes. El nivel Extra asigna más recursos a problemas complejos, mientras que Max va aún más lejos.
En cambio, los niveles bajo y medio reducen los recursos usados. Pueden ahorrar tiempo, pero también disminuyen la precisión esperada. Esta elección permite adaptar la IA según el presupuesto, la velocidad deseada y la complejidad del trabajo.
Este control aparece cerca del selector de modelo en claude.ai y Cowork. Esta opción está al alcance de todas las suscripciones. Anthropic indica que el nivel Alto consume casi tantos tokens como la configuración estándar de Opus 4.7, a la vez que ofrece mejores resultados. Los límites de tasa en Claude Code también se han elevado para absorber los usos de los niveles Extra y Max.
Seguridad y comparación con Claude Mythos Preview
El equipo de alineación de Anthropic también destaca progresos en el comportamiento del modelo. Los datos indican menos engaños y menos cooperación en casos de uso abusivo. Opus 4.8 también dejaría pasar cuatro veces menos bugs en su propio código sin reportarlos.
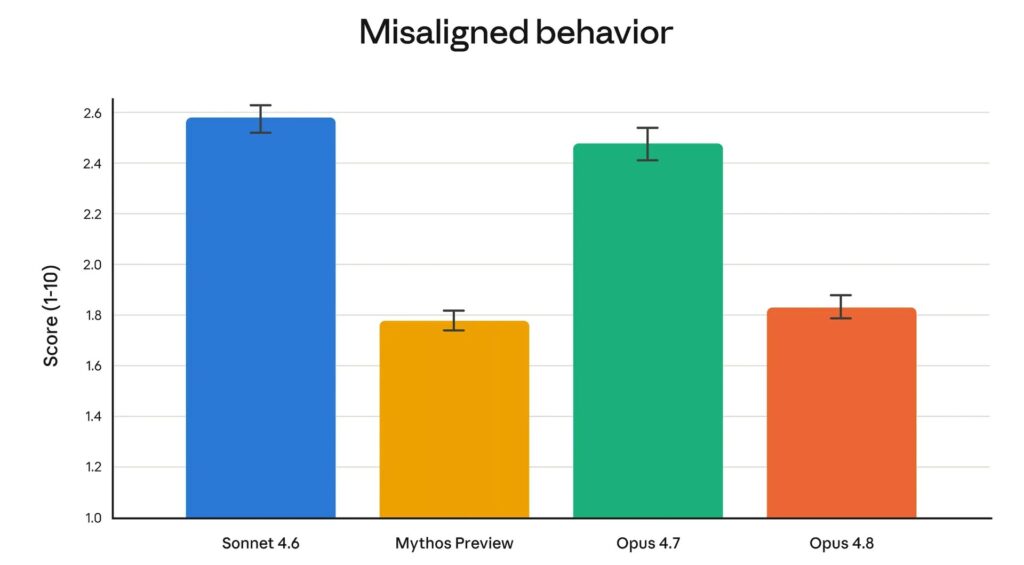
Estos resultados acercan a Opus 4.8 a Claude Mythos Preview en ciertos criterios de seguridad. Sin embargo, Mythos sigue presentándose como un modelo más colosal e inteligente que Opus. Solo está disponible en versión preliminar para algunas organizaciones seleccionadas del ámbito de la ciberseguridad, especialmente a través del proyecto Glasswing.
Este marco limitado se explica por sus capacidades avanzadas. El Instituto Británico de Seguridad de IA constató que Mythos podía realizar solo una simulación de ataque en red en 32 etapas. Esta tarea suele tomar 20 horas a equipos expertos en seguridad. Por esta razón, el modelo aún no se comercializa a gran escala.
A corto plazo, Opus 4.8 debería sobre todo reforzar la competencia entre Claude, GPT y Gemini. El desafío estará en el equilibrio entre costo, velocidad, precisión y seguridad. En este contexto, la inteligencia artificial ya no depende solo de las puntuaciones de pruebas, sino también del control ofrecido a los usuarios y los límites fijados al despliegue.
¡Maximiza tu experiencia en Cointribune con nuestro programa "Read to Earn"! Por cada artículo que leas, gana puntos y accede a recompensas exclusivas. Regístrate ahora y comienza a acumular beneficios.

Journaliste et rédacteur web passionné par l’univers des cryptomonnaies et des technologies Web3. J’y traite les dernières tendances et actualités afin de proposer un contenu de haute qualité à un large public du secteur.
Las ideas y opiniones expresadas en este artículo pertenecen al autor y no deben tomarse como consejo de inversión. Haz tu propia investigación antes de tomar cualquier decisión de inversión.