AI : Anthropic unveils Opus 4.8, just six weeks after Opus 4.7
The market for advanced models is evolving at a sustained pace, driven by frequent updates and increasingly precise tests. Anthropic returns with Opus 4.8, a version that aims for better performance without an increase in the standard price. In the AI sector, this announcement stands out for its programming results, new effort adjustments, and announced security improvements.

In brief
- Anthropic launches Opus 4.8 just six weeks after Opus 4.7, with better performance and unchanged standard pricing.
- The model improves on several benchmarks, notably SWE-bench Pro, where it reaches 69.2% compared to 64.3% for Opus 4.7.
- Opus 4.8 offers a fast mode, more expensive but announced as cheaper than the fast modes of previous versions.
- The new effort settings allow adapting the model according to task speed, accuracy, and complexity.
- Anthropic also highlights security progress, with less deception and fewer bugs left unreported.
Anthropic launches Opus 4.8 shortly after Opus 4.7
Just six weeks after the launch of Opus 4.7, Anthropic presents Opus 4.8 with a dazzling promise: to improve performance while keeping the same price. The model remains available at 5 dollars per million input tokens and 25 dollars per million output tokens. This stability provides a useful benchmark for users comparing costs between Claude versions.
However, the actual cost may vary depending on tasks. The new tokenizer uses more tokens to execute certain requests. Thus, a task performed with Opus may cost more than with Claude Sonnet. The latter remains less powerful but may suffice for daily uses or complex problems not related to advanced research.
Additionally, Anthropic offers a fast mode for Opus 4.8. This mode runs the same model at a speed 2.5 times higher. The price then rises to 10 dollars per million input tokens and 50 dollars per million output tokens. According to the company, this mode now costs three times less than on previous models.
AI: improved performance on benchmarks
The most noted result concerns SWE-bench Pro. This test measures an AI’s ability to solve complex software engineering problems in real codebases. Opus 4.8 reaches 69.2%, versus 64.3% for Opus 4.7. It also surpasses GPT-5.5, rated at 58.6%, and Gemini 3.1 Pro, rated at 54.2%.
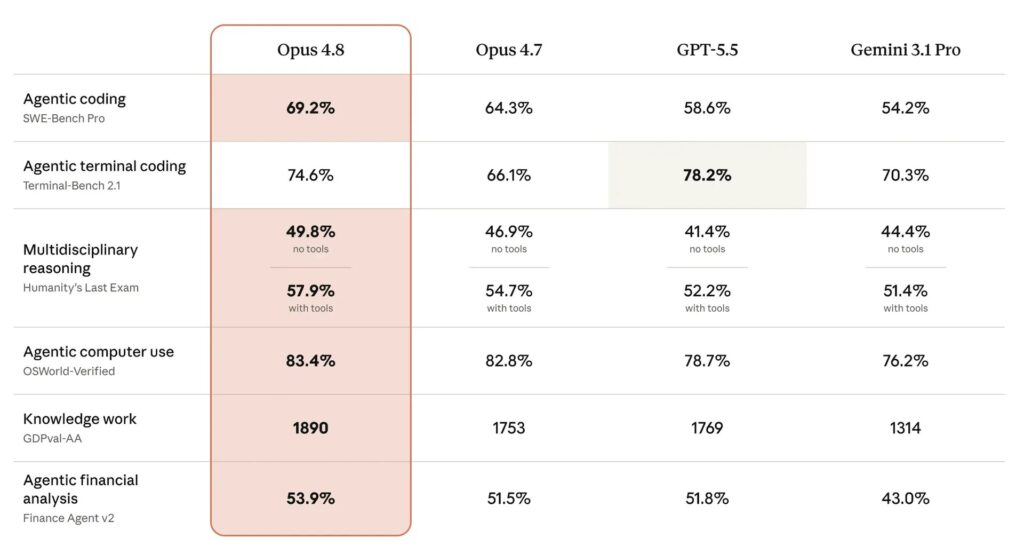
On Humanity’s Last Exam, the model also shows high scores. This questionnaire covers several academic disciplines with expert-level questions.
- Opus 4.8 achieves 49.8% without tools.
- Opus 4.8 reaches 57.9% with tools.
- GPT-5.5 scores 78.2% on Terminal-Bench 2.1.
- Opus 4.8 achieves 74.6% on Terminal-Bench 2.1.
- Opus 4.7 scored 66.1% on the same test.
- Opus 4.8 reaches 83.4% on OSWorld-Verified, versus 82.8% for Opus 4.7.
These results place the model ahead of the competitors cited in the Humanity’s Last Exam data. Results are more nuanced on Terminal-Bench 2.1, which evaluates command-line tasks performed by an AI. Despite its second place, Anthropic significantly improves Opus 4.7’s score. On OSWorld-Verified, the model progresses more slowly compared to the previous version.
Effort settings to better control Claude
Opus 4.8 gives users more control. They can adjust the model’s effort level according to task difficulty. The high level remains activated by default and suits most requests. The Extra level allocates more resources to complex problems, while Max goes even further.
Conversely, the Low and Medium levels reduce the resources used. They can save time but also reduce expected accuracy. This choice allows adapting the AI according to budget, desired speed, and task complexity.
This control appears near the model selector on claude.ai and Cowork. It remains available for all subscriptions. Anthropic indicates that the high level consumes almost as many tokens as the standard setting of Opus 4.7 while delivering better results. Rate limits in Claude Code were also raised to accommodate the use of Extra and Max levels.
Security and comparison with Claude’s Mythos Preview
Anthropic’s alignment team also highlights progress on model behavior. The data indicate less deception and less cooperation in case of misuse. Opus 4.8 would also let through four times fewer bugs in its own code without reporting them.
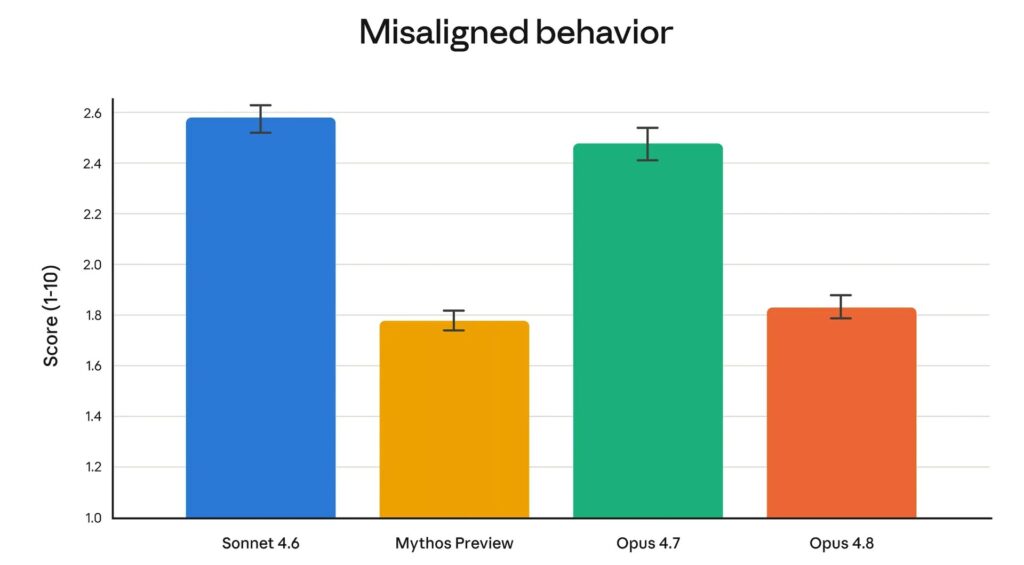
These results bring Opus 4.8 closer to Claude’s Mythos Preview on certain safety criteria. However, Mythos remains presented as a larger and smarter model than Opus. It is only available in a preview version for a few selected organizations in cybersecurity, notably through the Glasswing project.
Its advanced capabilities explain this limited framework. The UK AI Safety Institute found that Mythos could conduct a 32-step network attack simulation by itself. This task usually takes 20 hours for expert security teams. For this reason, the model is not yet commercially available on a large scale.
In the short term, Opus 4.8 should mainly strengthen competition among Claude, GPT, and Gemini. The challenge will hinge on balancing cost, speed, accuracy, and security. In this context, artificial intelligence no longer depends solely on test scores but also on the user control offered and deployment limits set.
Maximize your Cointribune experience with our "Read to Earn" program! For every article you read, earn points and access exclusive rewards. Sign up now and start earning benefits.

Journaliste et rédacteur web passionné par l’univers des cryptomonnaies et des technologies Web3. J’y traite les dernières tendances et actualités afin de proposer un contenu de haute qualité à un large public du secteur.
The views, thoughts, and opinions expressed in this article belong solely to the author, and should not be taken as investment advice. Do your own research before taking any investment decisions.