IA : Anthropic dévoile Opus 4.8, six semaines seulement après Opus 4.7
Le marché des modèles avancés évolue à un rythme soutenu, porté par des mises à jour fréquentes et des tests toujours plus précis. Anthropic revient avec Opus 4.8, une version qui vise de meilleures performances sans hausse du tarif standard. Dans le secteur de l’IA, cette annonce se distingue par ses résultats en programmation, ses nouveaux réglages d’effort et ses progrès annoncés en matière de sécurité.

En bref
- Anthropic lance Opus 4.8 seulement six semaines après Opus 4.7, avec de meilleures performances et un tarif standard inchangé.
- Le modèle progresse sur plusieurs benchmarks, notamment SWE-bench Pro, où il atteint 69,2 % contre 64,3 % pour Opus 4.7.
- Opus 4.8 propose un mode rapide, plus coûteux, mais annoncé comme moins cher que les modes rapides des versions précédentes.
- Les nouveaux réglages d’effort permettent d’adapter le modèle selon la vitesse, la précision et la complexité des tâches.
- Anthropic met aussi en avant des progrès en sécurité, avec moins de tromperie et moins de bogues laissés sans signalement.
Anthropic lance Opus 4.8 peu après Opus 4.7
Six semaines seulement après le lancement d’Opus 4.7, Anthropic présente Opus 4.8 avec une promesse éclatante : améliorer les performances tout en gardant le même prix. Le modèle reste proposé à 5 dollars par million de jetons d’entrée et 25 dollars par million de jetons de sortie. Cette stabilité donne un repère utile aux utilisateurs qui comparent les coûts entre les versions de Claude.
Cependant, le coût réel peut changer selon les tâches. Le nouveau tokenizer utilise davantage de jetons pour exécuter certaines demandes. Ainsi, un travail réalisé avec Opus peut coûter plus cher qu’avec Claude Sonnet. Ce dernier reste moins puissant, mais il peut suffire pour des usages quotidiens ou des problèmes complexes qui ne relèvent pas de la recherche avancée.
En parallèle, Anthropic propose un mode rapide pour Opus 4.8. Ce mode exécute le même modèle à une vitesse 2,5 fois supérieure. Le tarif passe alors à 10 dollars par million de jetons d’entrée et 50 dollars par million de jetons de sortie. Selon l’entreprise, ce mode coûte désormais trois fois moins cher que sur les modèles précédents.
IA : des performances en hausse sur les benchmarks
Le résultat le plus observé concerne SWE-bench Pro. Ce test mesure la capacité d’une IA à résoudre des problèmes complexes de génie logiciel dans de vraies bases de code. Opus 4.8 atteint 69,2 %, contre 64,3 % pour Opus 4.7. Il dépasse aussi GPT-5.5, noté à 58,6 %, et Gemini 3.1 Pro, noté à 54,2 %.
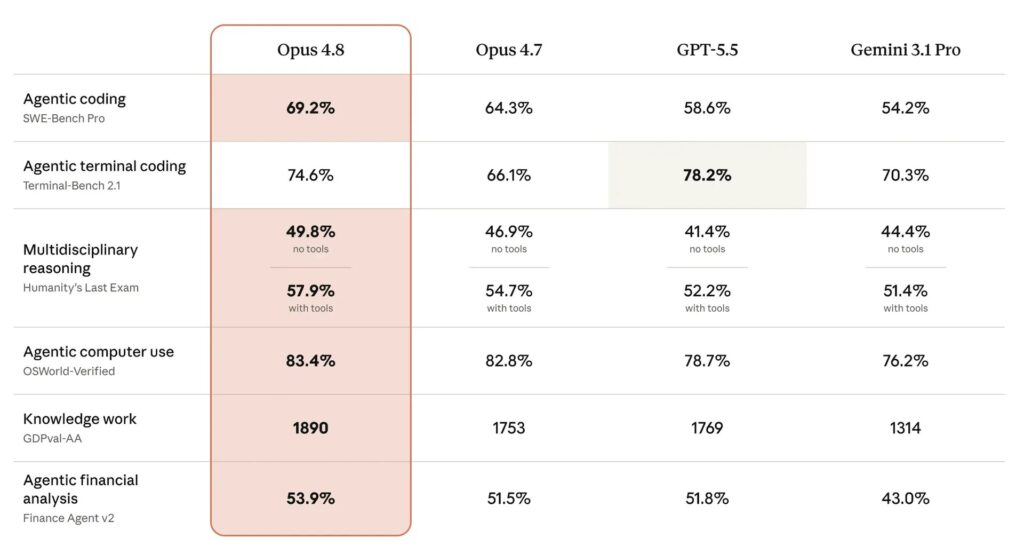
Sur Humanity’s Last Exam, le modèle affiche aussi des scores élevés. Ce questionnaire couvre plusieurs disciplines universitaires avec des questions de niveau expert.
- Opus 4.8 obtient 49,8 % sans outils ;
- Opus 4.8 atteint 57,9 % avec outils ;
- GPT-5.5 arrive à 78,2 % sur Terminal-Bench 2.1 ;
- Opus 4.8 obtient 74,6 % sur Terminal-Bench 2.1 ;
- Opus 4.7 affichait 66,1 % sur ce même test ;
- Opus 4.8 atteint 83,4 % sur OSWorld-Verified, contre 82,8 % pour Opus 4.7.
Ces résultats placent le modèle devant les concurrents cités dans les données fournies sur Humanity’s Last Exam. Les résultats restent plus nuancés sur Terminal-Bench 2.1, qui évalue les tâches en ligne de commande réalisées par une IA. Malgré sa deuxième place, Anthropic améliore nettement le score d’Opus 4.7. Sur OSWorld-Verified, le modèle progresse plus légèrement par rapport à la version précédente.
Des réglages d’effort pour mieux contrôler Claude
Opus 4.8 donne plus de contrôle aux utilisateurs. Ils peuvent régler le niveau d’effort du modèle selon la difficulté de la tâche. Le niveau Élevé reste activé par défaut et convient à la plupart des demandes. Le niveau Extra accorde plus de ressources aux problèmes complexes, tandis que Max va encore plus loin.
À l’inverse, les niveaux Faible et Moyen réduisent les ressources utilisées. Ils peuvent faire gagner du temps, mais ils diminuent aussi la précision attendue. Ce choix permet donc d’adapter l’IA selon le budget, la vitesse souhaitée et la complexité du travail.
Ce contrôle apparaît près du sélecteur de modèle dans claude.ai et Cowork. Il reste disponible pour tous les abonnements. Anthropic indique que le niveau Élevé consomme presque autant de jetons que le réglage standard d’Opus 4.7, tout en donnant de meilleurs résultats. Les limites de débit dans Claude Code ont aussi été relevées pour absorber les usages des niveaux Extra et Max.
Sécurité et comparaison avec Claude Mythos Preview
L’équipe d’alignement d’Anthropic met aussi en avant des progrès sur le comportement du modèle. Les données indiquent moins de tromperie et moins de coopération en cas d’usage abusif. Opus 4.8 laisserait aussi passer quatre fois moins de bogues dans son propre code sans les signaler.
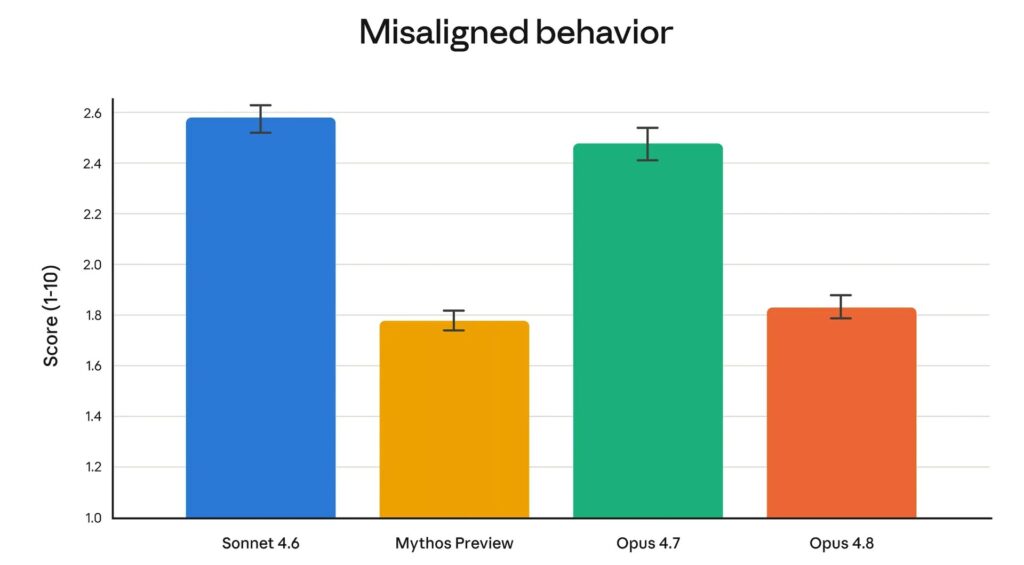
Ces résultats rapprochent Opus 4.8 de Claude Mythos Preview sur certains critères de sécurité. Toutefois, Mythos reste présenté comme un modèle plus vaste et plus intelligent qu’Opus. Il n’est disponible qu’en version préliminaire pour quelques organisations sélectionnées dans le domaine de la cybersécurité, notamment via le projet Glasswing.
Ce cadre limité s’explique par ses capacités avancées. L’Institut britannique de sécurité de l’IA a constaté que Mythos pouvait mener seul une simulation d’attaque réseau en 32 étapes. Cette tâche prend habituellement 20 heures à des équipes expertes en sécurité. Pour cette raison, le modèle n’est pas encore commercialisé à grande échelle.
À court terme, Opus 4.8 devrait surtout renforcer la concurrence entre Claude, GPT et Gemini. L’enjeu portera sur l’équilibre entre coût, vitesse, précision et sécurité. Dans ce contexte, l’intelligence artificielle ne dépend plus seulement des scores de tests, mais également du contrôle offert aux utilisateurs et des limites fixées au déploiement.
Maximisez votre expérience Cointribune avec notre programme 'Read to Earn' ! Pour chaque article que vous lisez, gagnez des points et accédez à des récompenses exclusives. Inscrivez-vous dès maintenant et commencez à cumuler des avantages.

Journaliste et rédacteur web passionné par l’univers des cryptomonnaies et des technologies Web3. J’y traite les dernières tendances et actualités afin de proposer un contenu de haute qualité à un large public du secteur.
Les propos et opinions exprimés dans cet article n'engagent que leur auteur, et ne doivent pas être considérés comme des conseils en investissement. Effectuez vos propres recherches avant toute décision d'investissement.